
Have you ever wondered if an AI can tell your favorite anime characters apart?
Developed as part of the IBM AI Engineering certification course, this project explores exactly that. Using PyTorch, I built and trained a Convolutional Neural Network (CNN) to perform Anime Face Classification. To test the waters, we’re starting with a head-to-head visual showdown: teaching the model to accurately distinguish between the characters anastasia and takao.
| Authors | Jedrzej Golaszewski |
|---|---|
| Title | Anime Face Classification |
| Status | Completed |
| Date | Dec 28, 2025 |
| Tech stack | PyTorch, Python |
| Links |
Dataset
The original dataset was used in the ‘AniWho’ study (Read Paper). We use the Kaggle distribution of this dataset.
Download: Anime Face Dataset by Character Name
Character Insights: Anastasia vs. Takao
When training a Convolutional Neural Network, the visual differences between classes are what allow the model to learn. In this dataset, our two subjects offer a great contrast in character design.

Anastasia typically features a cooler color palette, characterized by her signature ash-blonde/silver hair and bright blue eyes.

Takao, on the other hand, presents a striking contrast with much darker, often deep blue or black hair and sharper, more intense facial features. These distinct differences in color profiles, hair shapes, and eye designs provide excellent patterns for our CNN’s filters to pick up on.
Model Architecture:
To classify our anime faces, we define a custom Convolutional Neural Network (CNN). Our architecture is straightforward but effective: it uses two convolutional layers to extract spatial features (like the distinct shapes of eyes or hair), max-pooling layers to reduce the spatial dimensions, and fully connected layers to output our final character predictions.
But thats not all! A crucial component of any neural network is the activation function, which introduces non-linearity and allows the network to learn complex visual patterns. In this project, we will compare two variations of our model using different activation functions: ReLU (Rectified Linear Unit) and LeakyReLU.
While ReLU is standard and highly efficient, it can sometimes suffer from the “dying ReLU” problem, where neurons completely stop learning if they receive negative inputs. LeakyReLU attempts to solve this by allowing a small, non-zero gradient when the input is negative, potentially keeping more neurons active during training.
Here is our PyTorch implementation. We designed the network to accept the activation function as an initialization parameter, allowing us to easily create and compare both model_relu and model_lrelu:
class AnimeCNN(nn.Module):
def __init__(self, activation):
super(AnimeCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, 1, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64 * 16 * 16, 128)
self.fc2 = nn.Linear(128, 2)
self.activ = activation
def forward(self, x):
x = self.pool(self.activ(self.conv1(x)))
x = self.pool(self.activ(self.conv2(x)))
x = x.view(-1, 64 * 16 * 16)
x = self.activ(self.fc1(x))
x = self.fc2(x)
return x
model_relu = AnimeCNN(nn.ReLU())
model_lrelu = AnimeCNN(nn.LeakyReLU())
Model Training
We trained our models over 5 epochs using a standard training loop. During each epoch, the model processes batches of images in a dedicated training phase, calculating the error and updating its internal weights via backpropagation.
To ensure the network generalizes well to new images and isn’t simply memorizing the training data, we evaluate it at the end of every epoch. By briefly switching to an evaluation mode we calculate the loss on a separate validation dataset. Tracking both the training and validation losses side-by-side allows us to clearly monitor the learning progress and easily spot any signs of overfitting.
LeakyReLU vs ReLU
To compare the performance of the two activation functions, we analyzed their training loss curves and final evaluation metrics. Both models showed rapid initial convergence, quickly learning to distinguish between Anastasia and Takao.
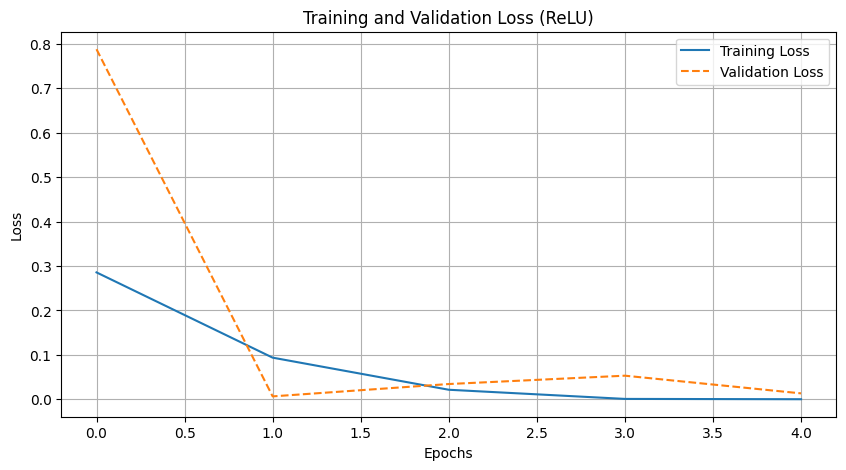

While LeakyReLU is theoretically designed to prevent the “dying ReLU” effect and stabilize gradient flow, our empirical results favored the standard approach. By epoch 5, the standard ReLU model outperformed its counterpart, achieving a perfect validation accuracy of 100.00% by correctly classifying all 50 validation images (20/20 and 30/30).
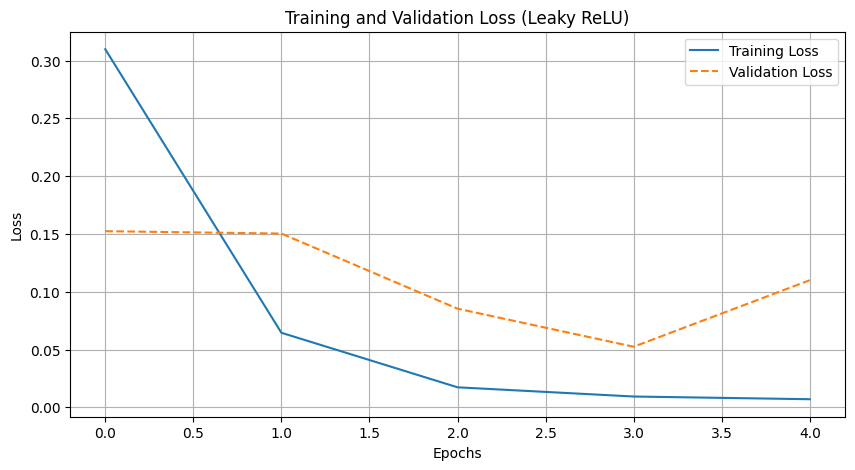

In contrast, the LeakyReLU model achieved a slightly lower accuracy of 96.67%, misclassifying just one image in the second class (29/30). Ultimately, for this straightforward dataset, the standard ReLU activation was highly effective at perfectly separating the two classes.